
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
Tags
- styled-component
- npx
- 반응형웹
- typescript
- AWS
- CDN
- Recoil
- graphql
- component
- docker
- scrapping
- go
- 정규표현식
- 웹크롤링
- javascript animation
- express
- 성능최적화
- cicd
- sequelize
- 회고
- socket.io
- route
- 웹팩
- Modal
- Redux
- react
- 포트포워딩
Archives
- Today
- Total
프로그래밍 공부하기
[Python] 웹크롤링 1 - BeautifulSoup와 requests 본문
0. BeautifulSoup, requests 설치


실습 1: 내가 만든 html에서 데이터 가져오기
from bs4 import BeautifulSoup
html="""
<html><body>
<h1>h1태그의 텍스트</h1>
<p>p1태그의 텍스트1</p>
<p>p태그의 텍스트2</p>
</body></html
"""
soup = BeautifulSoup(html, 'html.parser')
h1 = soup.html.body.h1
p1 = soup.html.body.p
p2 = p1.next_sibling.next_sibling
print("h1 = " + h1.string)Beautiful Soup는 html의 각 요소와 데이터에 접근하고 추출할 수 있다.
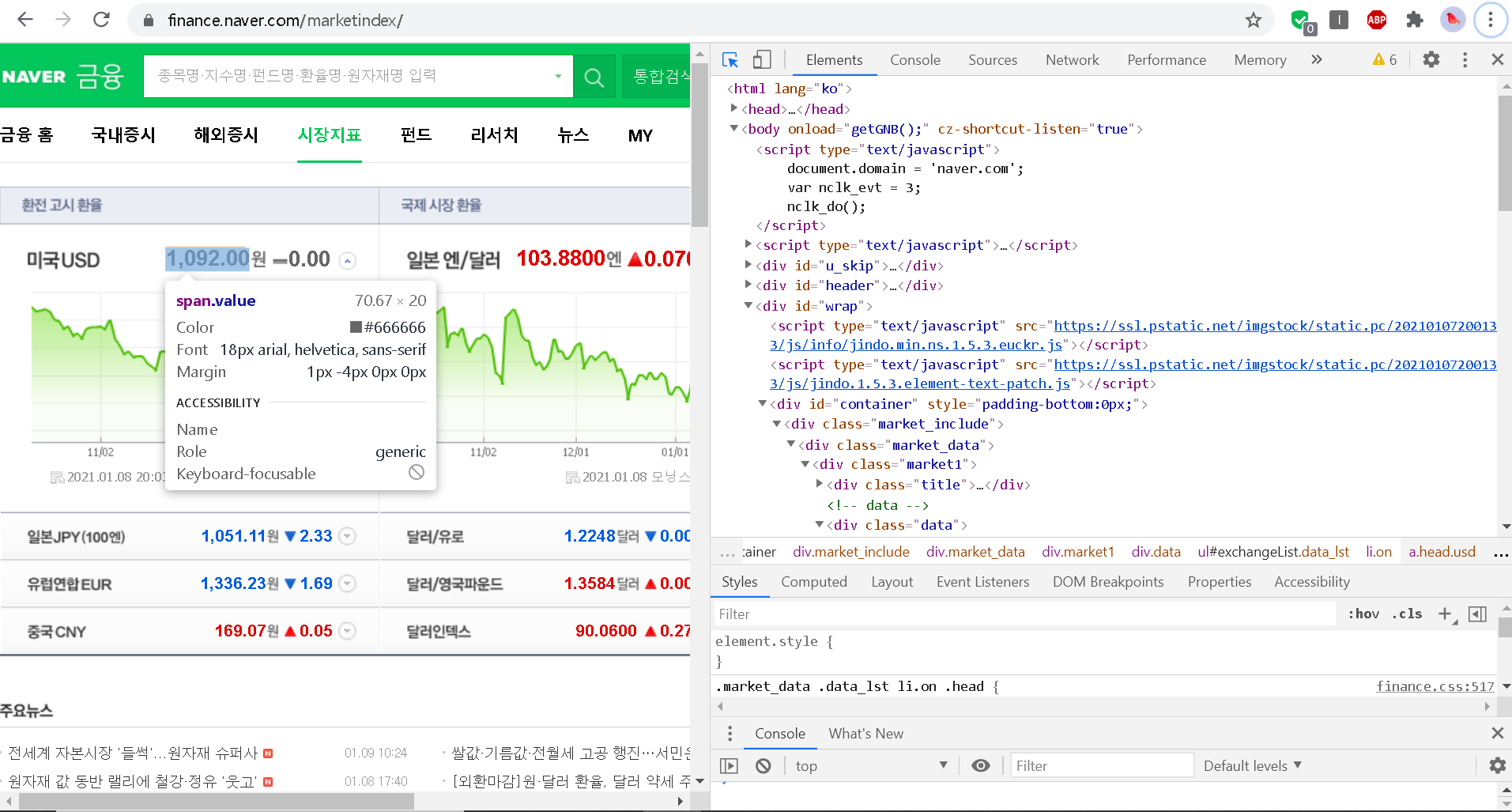
실습2: 외부 페이지에서 데이터 가져오기 - 환율 정보
from bs4 import BeautifulSoup
import urllib.request as req
url = "http://finance.naver.com/marketindex/"
res = req.urlopen(url)
soup = BeautifulSoup(res, "html.parser")
price = soup.select_one("div.head_info > span.value").string
print("환율=", price)requests를 이용하여 URL을 요청하고 응답받아 이를 BeautifulSoup를 사용하여 사이트의 요소에 접근할 수 있다. css선택자의 경우 웹브라우저의 개발자도구(F12)를 참고하여 작성한다. 완성된 코드는 cron을 명령어로 코드를 주기적으로 수행시켜 데이터를 원하는 기간마다 수집하는 식으로 활용 가능하다.
실습3. 외부 페이지에서 데이터 가져오기 - 네이버 뉴스 제목

BeautifulSoup는 find, find_all, select_one 등 html 요소를 선택하기 위한 다양한 메소드를 제공하고 있다. 이러한 메소드들을 활용하여 원하는 정보를 가져올 수 있다.
참고서적
파이썬을 이용한 머신러닝, 딥러닝 실전 개발 입문
BEAUTIFULSOUP, SCIKIT-LEARN, TENSORFLOW를 사용하여 실무에 머신러닝/딥러닝을 적용해 보자!인공지능, 머신러닝, 딥러닝은 바둑, 의료, 자동차 등 이미 다양한 분야에서 성공적인 성과를 보여주고 있습니
book.naver.com
'Web > [Other] Language' 카테고리의 다른 글
| Go (0) | 2021.03.12 |
|---|---|
| [Python] 웹크롤링 2 - 로그인 (0) | 2021.02.28 |
| [Python] 아스키코드변환: ord, chr (0) | 2021.01.08 |
| [Python] //연산과 %연산의 결과는 다른 언어와 다르다. (0) | 2020.12.19 |
'Web/[Other] Language' Related Articles
more


Comments