cheerio를 이용한 javascript 스크래핑

나는 노래방가는 것을 좋아한다. 하지만 막상 노래방에 가면 어떤 노래를 불러야할지 고민하다 인기차트에 있는 노래만 부르고 오게 된다. 그런데 이 인기차트도 변동이 크지 않기 때문에 결국 노래방에 갈 때마다 같은 노래만 부르고오기 일쑤이다. 이러한 고민에서 나만의 노래번호 리스트를 만드는 프로젝트를 생각해냈고, 이 의견이 받아들여져서 퍼스트 프로젝트로 내 아이디어를 구현해보게 되었다.
이 프로젝트에서 핵심은 노래방 업체의 노래번호를 가져오는 것이다. 노래방 업체가 API를 제공해주면 좋겠지만, 그렇지 않기 때문에 노래방 업체가 제공하는 노래검색 결과를 스크래핑하여 이를 제공하는 스크랩 서버를 따로 만들기로 하였다.
1. URL
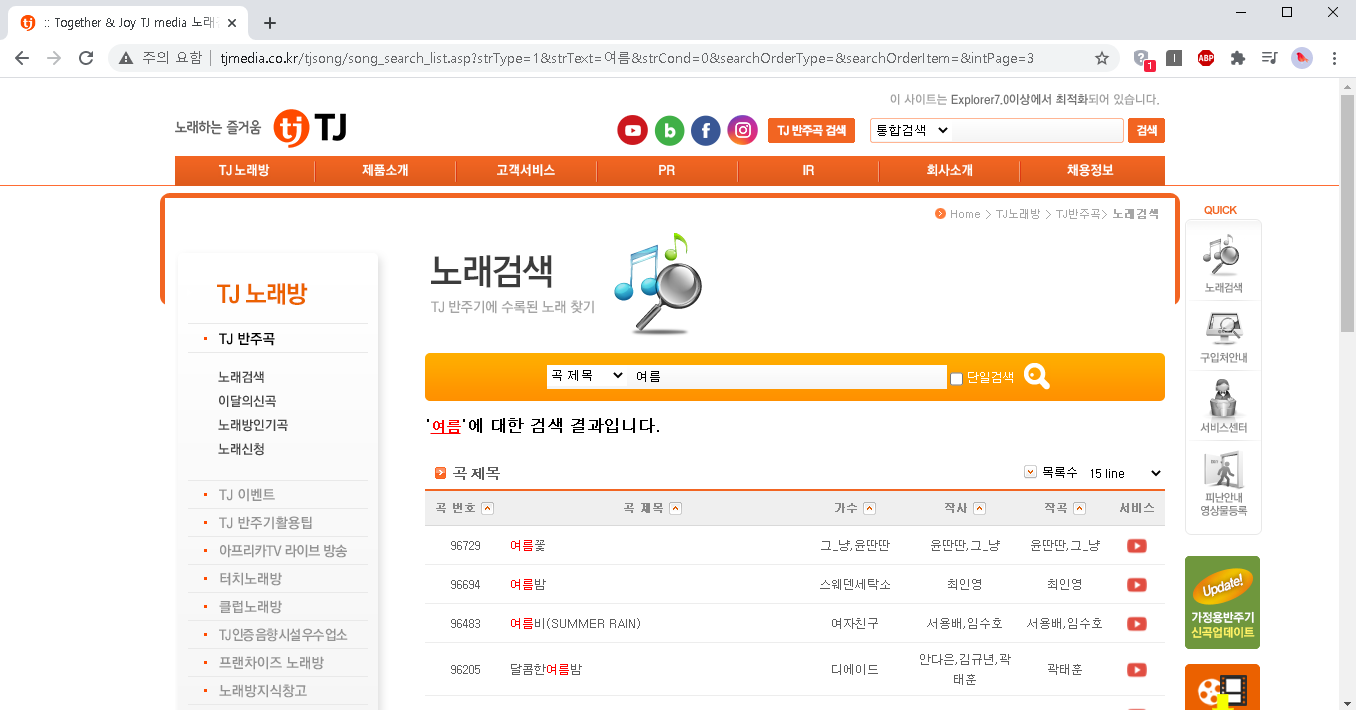
노래방 업체에서 노래제목을 검색한 결과는 위와 같다. 여기서 주목할 점은 URL이다. 내가 제목으로 '여름'을 검색한 결과를 얻고싶을 때 노래방 업체에 가서 굳이 검색하지 않아도 위의 URL에 접속하면 결과를 바로볼 수 있을 것이다. 즉, 저 URL이 스크래핑의 타겟이 되는 것이다.
http://www.tjmedia.co.kr/tjsong/song_search_list.asp?strType=1&strText=%EC%97%AC%EB%A6%84&strCond=0&strSize01=50&intPage=2
URL을 더 자세히 분석해보자 www.tjmedia.co.kr/tjsong/song_search_list.asp 까지는 어떤 검색결과이든 공통인 URL이고, 그 이후로는 검색 요청 데이터를 QueryParameter로 엮은 것이다. strText는 검색 키워드(인코딩), intSize01은 한 페이지에 보여질 노래 갯수, intPage는 검색 결과 페이지를 의미한다.
http://www.tjmedia.co.kr/tjsong/song_search_list.asp?strType=2&strText=%EC%95%84%EC%9D%B4%EC%9C%A0&strCond=0&strSize02=50&intPage=2
가수검색 URL은 위와 같다. 제목 검색 URL과 비교해보았을 때 strType의 값이 2로 변경되었고, strSize키가 strSize01에서 strSize02로 변경되었다. 즉, 해당 부분이 검색 종류를 의미한다는 것을 알 수 있다.
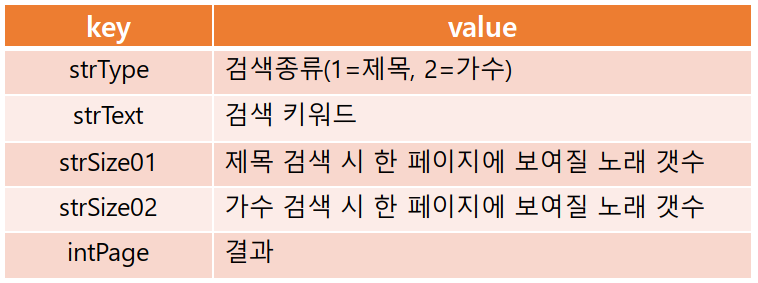
노래 검색 URL의 Query Parameter를 정리하면 위와 같다. 나는 이제 www.tjmedia.co.kr/tjsong/song_search_list.asp? 라는 주소 뒤에 해당 Query Parameter를 변경하는 것으로 검색결과 페이지에 접근할 수 있게 되었다.
const URL = 'http://www.tjmedia.co.kr/tjsong/song_search_list.asp';
const getTitleURL = (title, rowOfNum, page) => {
const URL_PARAMES = `?strType=1&strText=${encodeURI(title)}&strSize01=${rowOfNum}&intPage=${page}`;
return URL + URL_PARAMES;
};
const getSingerURL = (singer, rowOfNum, page) => {
const URL_PARAMES = `?strType=2&strText=${encodeURI(singer)}&strSize02=${rowOfNum}&intPage=${page}`;
return URL + URL_PARAMES;
};
요청에 따라 URL을 만드는 코드는 위와 같다.
2. axios and cheerio
검색 결과 페이지에서 내가 원하는 정보는 곡번호~서비스에 해당하는 부분이다. 이 부분을 어떻게 가져올 수 있을까? 웹 브라우저에서 해당 페이지에 접속한 상태라면 콘솔창에서 JavaScript의 document.querySelector()를 이용하여 클래스 선택자로 해당 HTML 요소를 특정하고 textContent 속성으로 가져올 수 있을 것이다. 웹 브라우저가 아닌 환경에서도 axios와 cheerio를 사용하면 이러한 작업을 똑같이 수행할 수 있다.
1) axios
const getHTML = async (url) => {
try {
return await axios.get(url);
} catch (error) {
return new Error(`${error.name}: ${error.message} \n${error.stack}`);
}
};axios로 get요청을 보낸 결과는 브라우저에서 해당 주소를 입력한 결과와 동일하다. 즉, 위에서 얻은 검색 요청 URL로 get 요청을 보내면 결과 페이지의 HTML을 얻어올 수 있는 것이다.
2) cheerio
<ul id="fruits">
<li class="apple">Apple</li>
<li class="orange">Orange</li>
<li class="pear">Pear</li>
</ul>cheerio는 HTML에서 document.querySelector()처럼 HTML 요소를 골라낼 수 있는 라이브러리이다. 위와 같은 페이지가 있다면 cheerio는 다음과 같이 활용할 수 있다.
const cheerio = require('cheerio');
const $ = cheerio.load('<ul id="fruits">...</ul>');
$.html(); //HTML Load
//=> <html><head></head><body><ul id="fruits">...</ul></body></html>
$('.apple', '#fruits').text();
//=> Apple
$('ul .pear').attr('class');
//=> pear
$('li[class=orange]').html();
//=> Orange먼저 cheerio.load()를 이용하여 HTML 태그 요소들을 $라는 변수에 할당한다. 그 후 css 선택자를 이용하여 원하는 HTML요소를 선택한 후 text(), attr(), html() 등의 메소드를 적절히 사용하면 내가 원하는 정보를 가져올 수 있다.
3) 구조
const searchSongs = async (way, keyword, rowOfNum = 15, page = 1) => {
const URL = way === TITLE ? getTitleURL(keyword, rowOfNum, page) : getSingerURL(keyword, rowOfNum, page);
return await getHTML(URL)
.then(html => {
const $ = cheerio.load(html.data);
const results = extractSong($);
const page = extractPage($);
return {
results,
page,
};
})
.then(result => {
return result;
});
};바로 cheerio로 원하는 정보를 가져오기 전 호출될 구조부터 작성해보자. 내가 구현할 것은 '검색 유형', '키워드', '한 페이지에 보여질 노래 수', '페이지'를 받으면 노래방 업체에서 해당 검색 결과 페이지에서 검색 결과 데이터를 가져오는 것이다. 이 때 검색 결과는 노래 뿐만 아니라 페이지 수도 포함되어 있으므로 이 부분을 따로 찾을 수 있도록 분리하였다. 해당 데이터를 찾은 후에는 객체로 만들어서 리턴해줄 것이다.
axios로 검색 결과 페이지 URL로 get 요청을 보내면 결과 페이지의 HTML을 받을 수 있다. 이를 cheerio.load()를 사용하여 $라는 변수에 결과 페이지의 모든 HTML 태그 요소들을 할당한다. 이 후 extractSong(), extractPage()라는 함수에서 CSS 선택자를 활용하여 결과 노래배열과 페이지 데이터를 리턴할 예정이다.
3. cheerio and CSS Selector
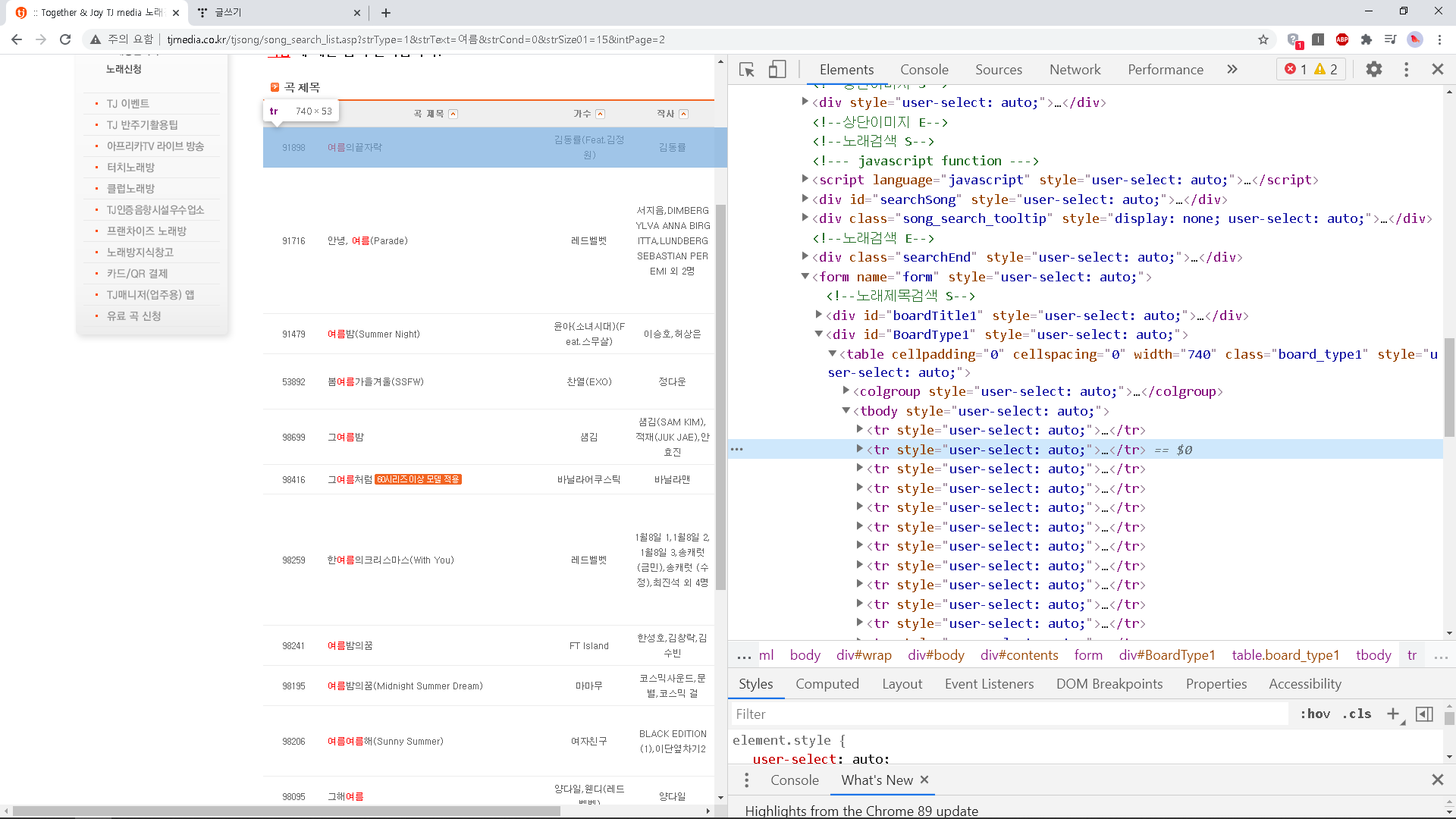
내가 원하는 부분의 데이터를 찾기 위해 먼저 크롬의 개발자 도구를 활용해보자. 크롬 개발자 도구를 이용하면 페이지의 어떤 부분이 어떤 HTML 요소인지 쉽게 찾을 수 있다. 내가 원하는 노래 검색 결과는 데이터 위 캡쳐에서 파란 색으로 표시된 부분부터이다. 이때 가장 위의 tr은 테이블의 헤더에 해당하는 부분이므로 제외시킨다.
$('#BoardType1 > table > tbody > tr:not(:first-child)').text()찾은 검색 결과 태그를 CSS 선택자로 만든 후 cheerio에 적용하여 텍스트만 추출하는 코드는 위와 같다.
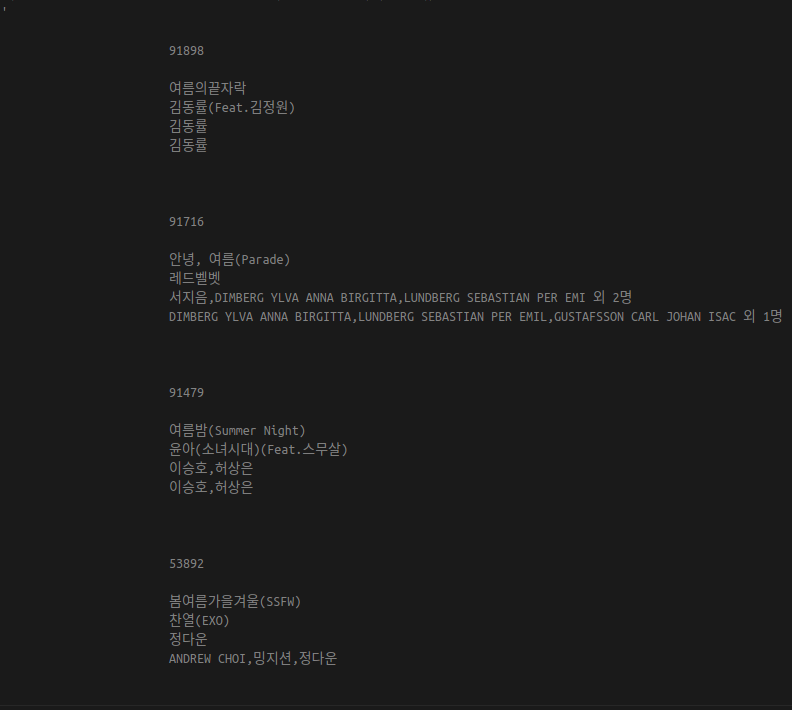
위 코드를 적용한 결과는 위와 같다. 데이터 텍스트는 잘 추출되지만 불필요한 탭 공백이 발생한다. 이들은 정규표현식으로 어느정도 제거해보겠다.
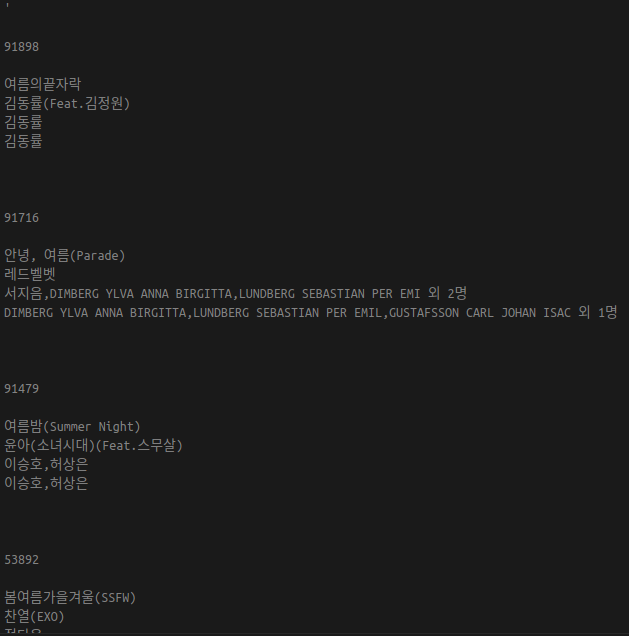
$('#BoardType1 > table > tbody > tr:not(:first-child)').text().replace(/[\t]/g, '')탭을 제거하니 위와 같은 결과가 발생한다. 줄바꿈을 제거하지 않는 이유는 줄바꿈은 각 노래와 속성들을 구분할 수 있는 기준으로 삼을 수 있기 때문이다.
'
91898
여름의끝자락
김동률(Feat.김정원)
김동률
김동률
91716
안녕, 여름(Parade)
레드벨벳
서지음,DIMBERG YLVA ANNA BIRGITTA,LUNDBERG SEBASTIAN PER EMI 외 2명
DIMBERG YLVA ANNA BIRGITTA,LUNDBERG SEBASTIAN PER EMIL,GUSTAFSSON CARL JOHAN ISAC 외 1명
91479
여름밤(Summer Night)
윤아(소녀시대)(Feat.스무살)
이승호,허상은
이승호,허상은
...'먼저 각 노래를 분리시켜보자. 결과 텍스트를 분석해보면 곡번호 앞에 한 번의 줄바꿈, 작곡가 뒤에 두 번의 줄바꿈이 항상 존재하는 것을 알 수 있다. 즉, 하나의 노래는 9줄의 텍스트로 이루어져 있는 것이다.
이제 각 노래에서 속성들을 분리해보자. 이들은 단순히 줄바꿈을 기준으로 분리할 수 있다. 단, 해당 데이터가 공백('')일 때를 제외하고 말이다.
const getFormatedSongArr = (arr) => {
const resultArr = [];
for (let i = 0; i < arr.length - 9; i += 9) {
let song = [];
for(let j = i; j < i + 9; j++) {
if(arr[j] !== '') {
song.push(arr[j]);
}
}
resultArr.push(song);
}
return resultArr;
};
const extractSong = ($) => {
const arr = $('#BoardType1 > table > tbody > tr:not(:first-child)').text().replace(/[\t]/g, '').split('\n');
const formatedArr = getFormatedSongArr(arr);
//....
}문자열을 처리하기 쉽게 줄바꿈을 기준으로 split한 배열로 만든 뒤 이중 for문을 이용하여 각 노래와 속성를 분리시켰다. 각 노래는 9줄로 구성되어있기 때문에 먼저 9줄씩 끊은 후 그 안에서 공백을 제외한 나머지 요소들을 하나의 배열에 담은 후 이를 결과 배열에 넣어주었다.

처리결과 내가 원하는대로 예쁘게 정리된 데이터를 얻을 수 있었다. 이들은 항상 곡번호, 제목, 가수, 작사, 작곡 순이므로 reduce와 구조분해할당을 이용하여 객체로 만들어 리턴하자.
const extractSong = ($) => {
const arr = $('#BoardType1 > table > tbody > tr:not(:first-child)').text().replace(/[\t]/g, '').split('\n');
const formatedArr = getFormatedSongArr(arr);
return formatedArr.reduce((acc, cur) => {
const [songNum, title, singer, writer, composer] = cur;
acc.push({
songNum,
title,
singer,
writer,
composer,
link: 'https://www.youtube.com/user/ziller/search?query=' + songNum
});
return acc;
}, []);
};extractSong의 전체 코드는 위와 같다. link는 노래방 업체가 해당 노래를 유튜브로 MR을 제공하는 페이지인데, 항상 같은 패턴의 URL을 사용하므로 직접 만들어서 리턴하였다.

성공적으로 내가 원하는 결과가 나왔다! 페이지 또한 위와 같은 방식으로 데이터를 구할 수 있으므로 생략하겠다. 스크래핑 전체 코드는 github에서 볼 수 있다.